The “Nation, Genre and Gender” Project at UCD is currently creating a large digital corpus of Irish and English novels from the period 1800–1922. Our objective is to compare gender, genre and the nationality of the author or setting in shaping social structures in fiction, building on ideas from researchers such as Franco Moretti who have advocated the “distant reading” approach to studying literature from a macro level viewpoint. As part of this, we are looking at how techniques from Social Network Analysis (SNA), often applied to online networks such as Twitter and Facebook, can be applied to provide a new perspective on literary texts. A range of interesting recent work has looked at analysing fiction in this way, from mapping Shakespeare’s tragedies to visualising the universe of Marvel comics. In our case, we are interested in exploring the social structures in 19th-20th century literature. Here I will outline how we go from the original text of a novel such as Oliver Twist by Charles Dickens to a visualisation of the final social network
Corpus Annotation
The first step of the analysis process involves the annotation of the novels, where literary scholars from the UCD Humanities Institute identify character references in the text of each novel, as retrieved from Project Gutenberg. The annotation process itself consists of a number of steps. Firstly, a character dictionary is constructed, which includes a single entry for each unique character in the novel, with their definitive name and a complete list of all of their aliases. For instance, the character Bill Sikes in Oliver Twist is referred to by a number of aliases, including “Mr. Sikes”, “William Sikes”, and “the murderer”. We also annotate characters with attributes such as gender, class, occupation, and religion. This task is performed not only for major characters, but also for the minor characters which make up the novel’s wider society. Once the dictionary has been compiled, all instances of a character’s aliases in the novel text are replaced with their definitive name.
Network Construction
Once a novel has been annotated, we create detailed character networks to map the society of the novel. A node is created for each character in the novel’s character dictionary. Then we tokenise each chapter in the previously-annotated text of the novel, and count all co-occurrences of pairs of character definitive names. Note that we choose to use all co-occurrences rather than only considering direct conversation between a pair of characters, as this allows us to capture a wide variety of types of interactions and associations between characters. We then create a weighted character network for the chapter, where an edge exists between a pair of characters if they co-occurred at least once during the chapter. The weight on the edge corresponds to the number of co-occurrences between the pair. An example of a small character network for Chapter 6 of Oliver Twist is shown below. A thicker edge indicates thats two characters co-occurred more frequently in that chapter.
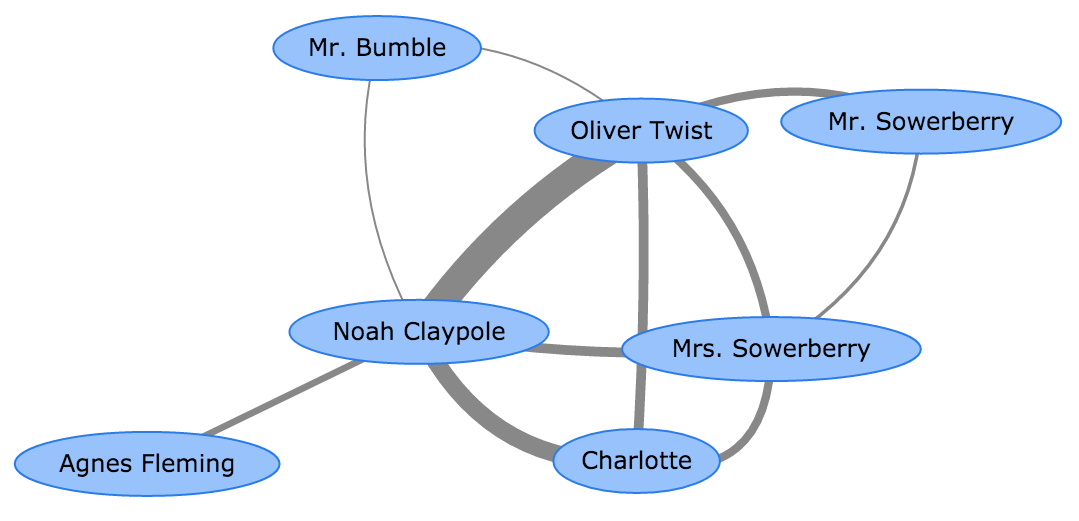
Once we have processed each chapter, we construct an overall character network for the entire novel by combining the networks from all chapters. In this overall network, the weight on an edge corresponds to the total number of co-occurrences between the pair across all chapters.
Network Visualisation
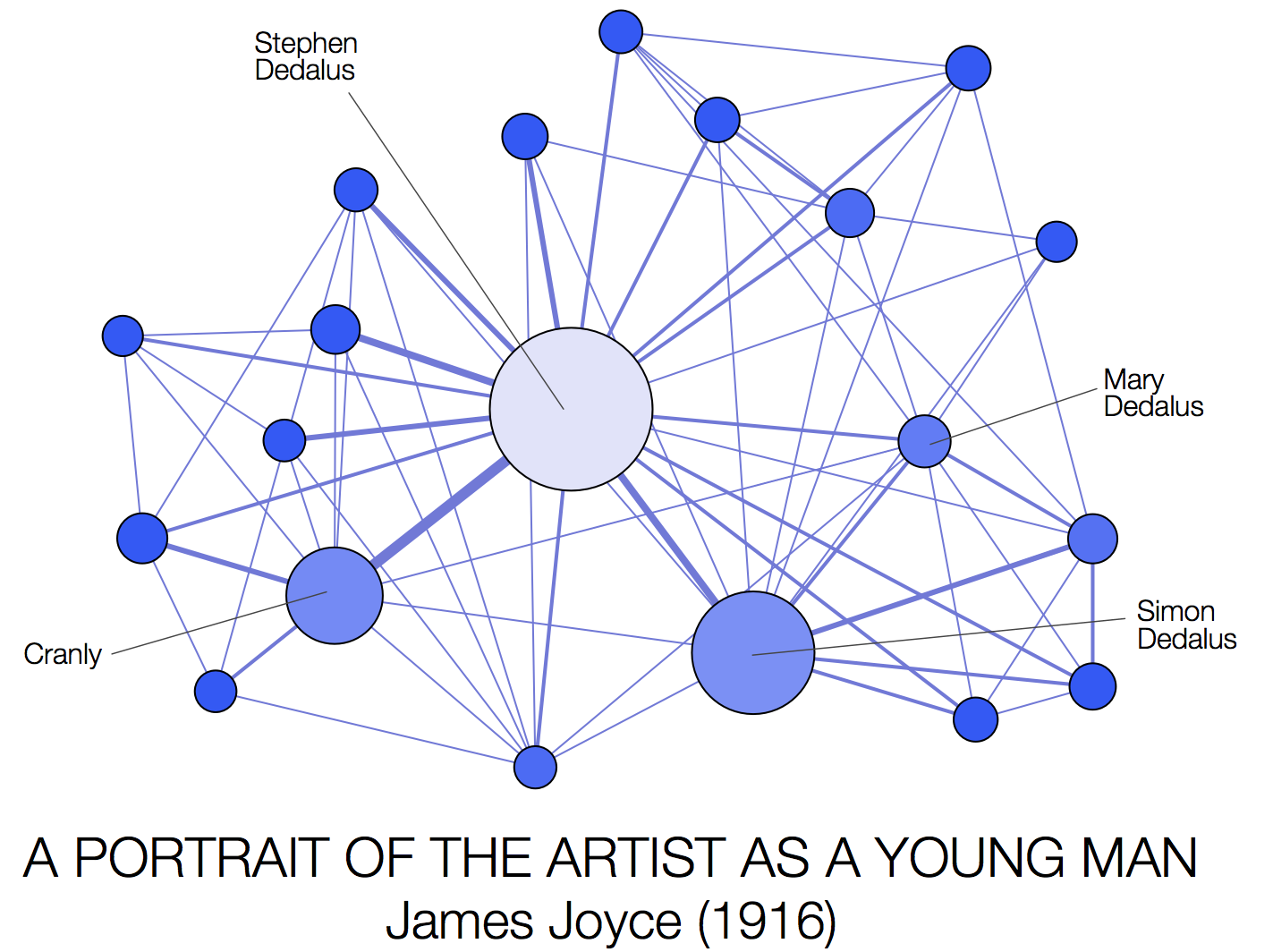
To actually visualise the resulting character networks, we use the open source tool Gephi, applying a force directed layout. A number of different example networks are shown below for four well known novels from Charles Dickens, Bram Stoker, Arthur Conan Doyle, and James Joyce respectively. In each case, we show the top 20 most prominent characters, as ranked by their weighted degree (i.e. the sum of the weights on the edges connected to them). The size and colour of each node is also proportional to the weighted degree.
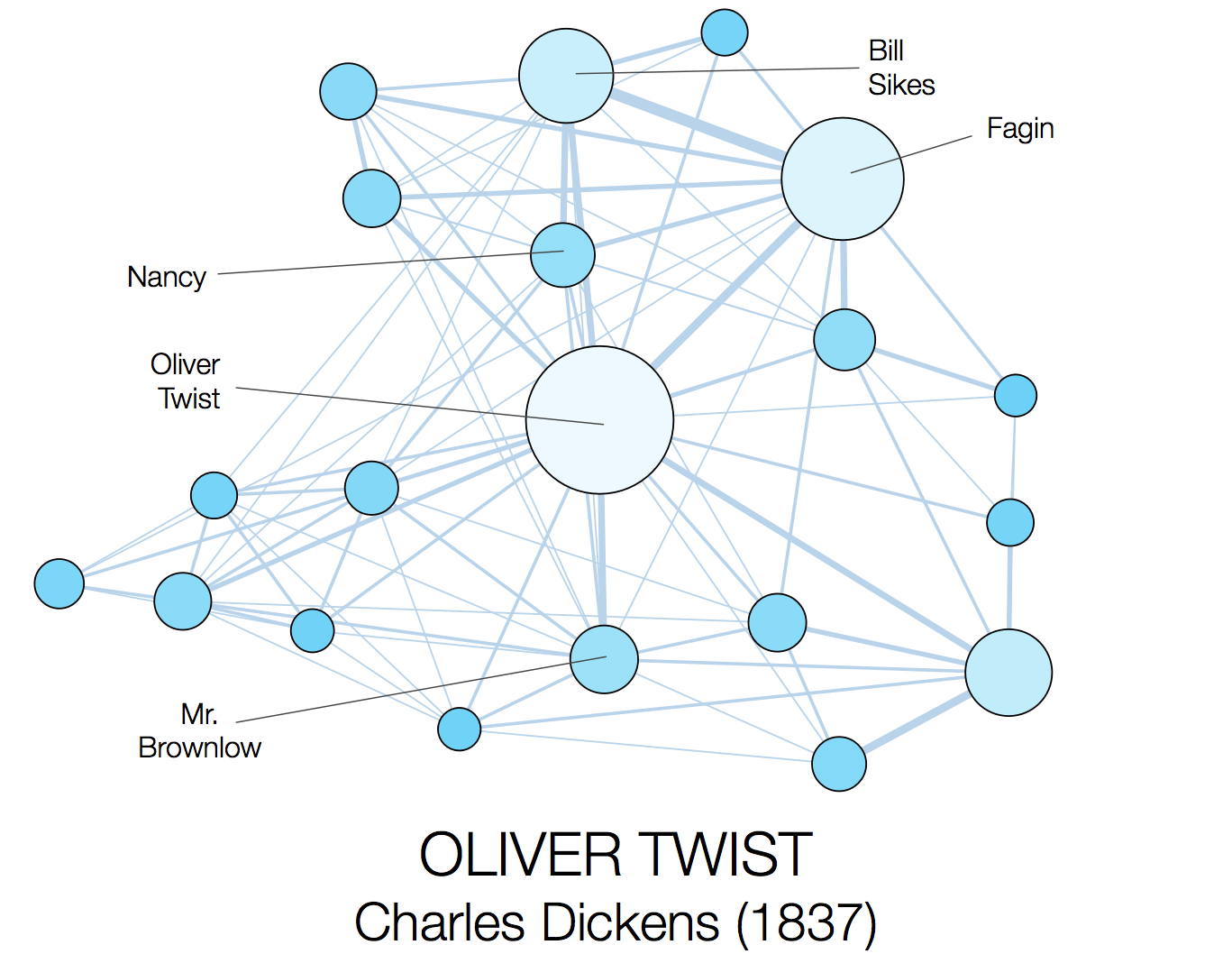
|
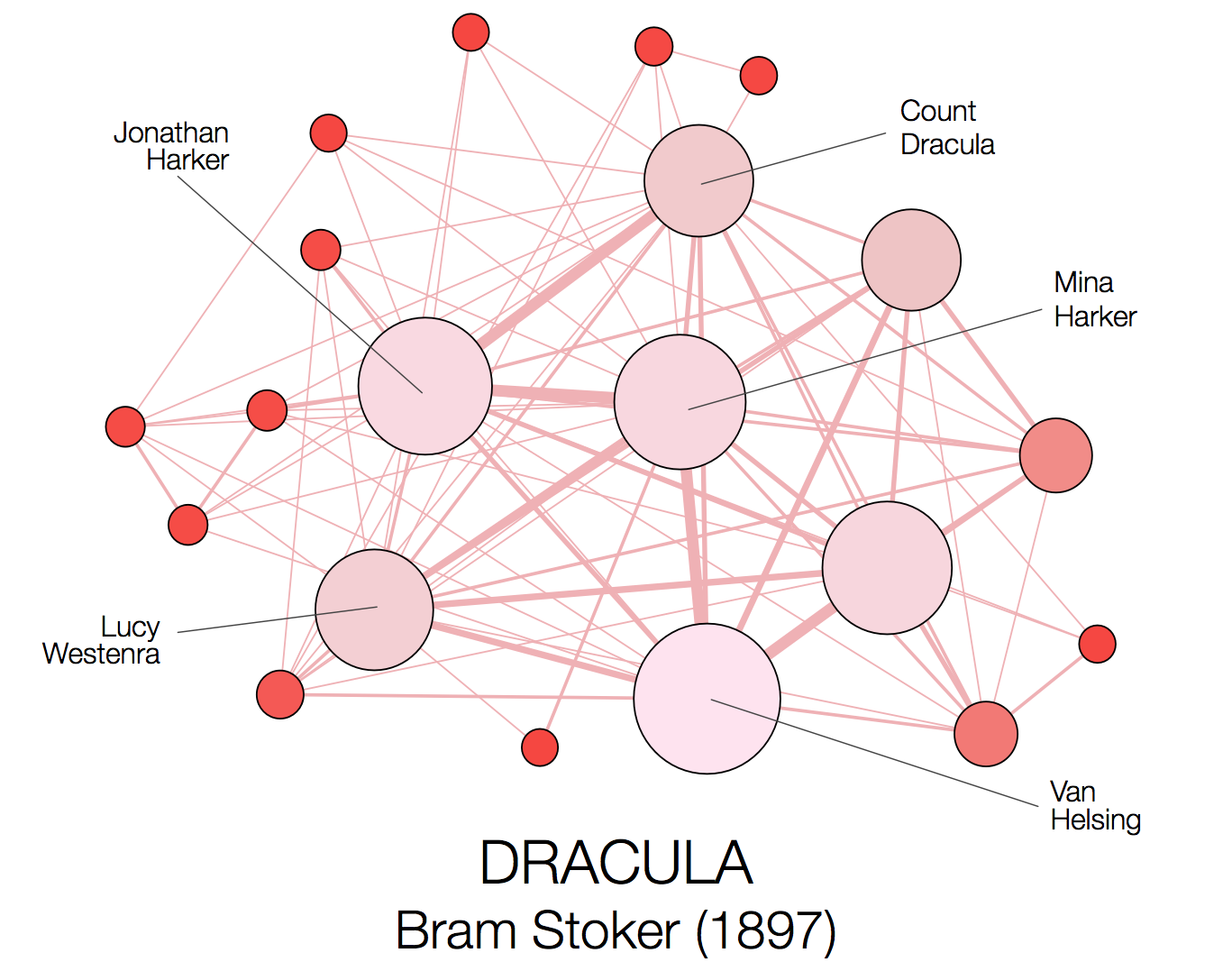
|
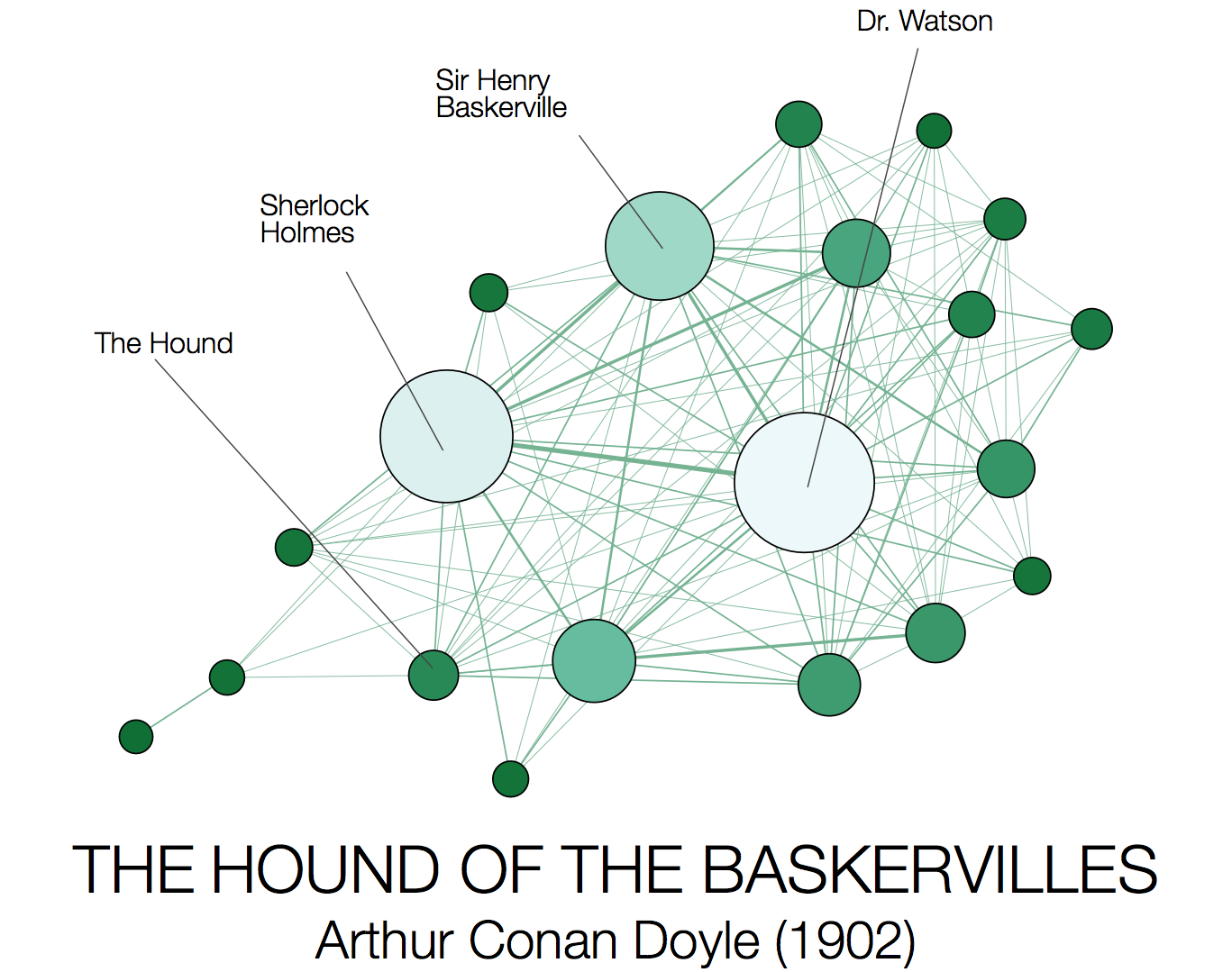
|
|
Further Analysis
Representing literary works in network form allows us to explore texts from authors such as Joyce and Dickens in a way that is independent of language and give us a “birds eye” visualisation that is accessible to non-experts. It also allows us to benefit from existing research, in areas such as community detection and ego network analysis, potentially providing new tools in the practice of distant reading. By adding attribute information, such as gender and class, to nodes and edges, we can also make interesting comparisons between novels from different authors and genres. We aim to use these character networks to explore and test a range of existing literary hypotheses, and also make these novels more accessible to students and researchers.